
About These Articles:
SVM的学习,可以查询到大量的相关文章、视频,并且在几本经典的书(西瓜书,统计学习方法等)中也有相应的解读。本文为个人总结回顾。
第二篇(本文)文章里涉及到的是SVM的核心知识,所以在理解了第一篇的基础上,我们可以进一步深入学习SVM。上一篇里我们说到SVM在数据线性可分情况下的计算,但是在实际应用中,数据往往是非线性可分的,此时该如何处理?
传送门:
简介与线性可分情况分析,最后附有详细推导过程与注解。
VC维,非线性可分SVM,核技巧,常用核函数,软间隔,总结。
VC维
关于VC维的定义与理解,Google上有很多详尽的Blog说明,这里我只翻译一段Wiki上的解释。“VC维度(Vapnik-Chervonenkis维)是可以通过统计分类算法学习的函数空间的容量(复杂性,表达能力,丰富性或灵活性)的度量。 它被定义为算法可以破碎的最大点集的基数。”
在SVM中,我们关注的是,两类点线性不可分时,我们将其投射到高维空间,投射到多少维的空间之后,它们就线性可分了呢?如何证明呢,理解了VC维的概念,我们就可以知道对于 $R^n$ 维的向量,VC维是$n+1$的时候,一定可以找到一个超平面将其分开。
非线性可分
非线性问题往往不好求解,所以希望能用解线性分类问题的方法解决这个问题。
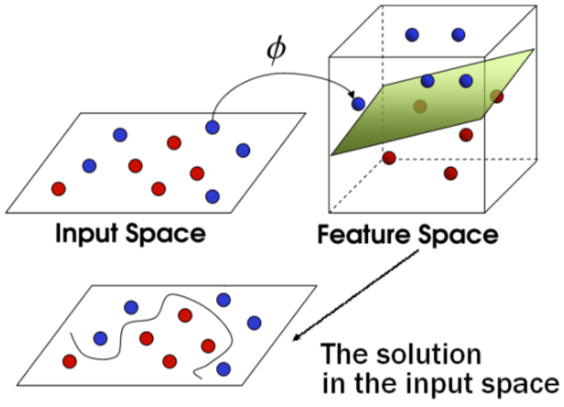
核心思想:使用一个映射函数$\phi(x)$(非线性变化)将我们的点映射到足够用一个超平面将其分开的维度。
*Input Space*: 输入的点$x_i$所在的空间
*Feature Space*:映射后$\phi(x)$所在的空间
例如,下图左,一个一维非线性可分的数据,映射到二维之后(下图右),线性可分。
现在,我们将问题从非线性可分转化到线性可以,只需要引入$\phi(x)$代替原本的$x$。从而,原本的优化问题:
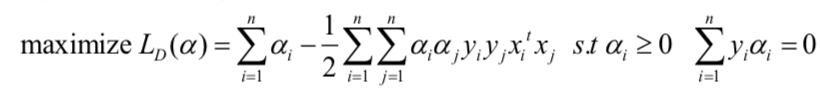
变为了:
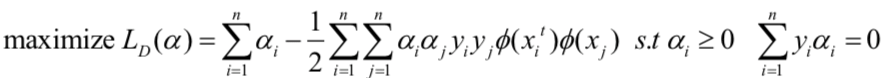
相应的,决策函数变为:
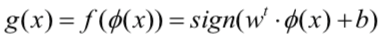
算法描述:
用线性分类方法求解非线性分类问题分为两步:
- 首先使用一个变换将原空间的数据映射到新空间
- 然后在新空间里用现象分类学习方法从训练数据中学习分类模型
核技巧 (Kernel Trick)
再回顾到我们现在的优化问题:
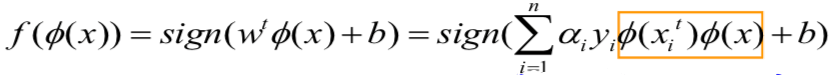
以及对应的决策函数:
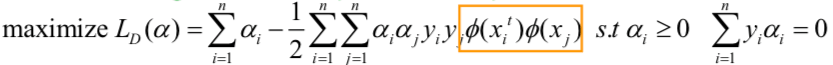
我们发现并不需要明确知道我们的映射函数或者新空间的维度,因为我们只需要计算它们的点积!
这里我们引入核函数的定义:
核函数: 设$\chi$是输入空间(欧氏空间$R^n$的子集或离散集合),又设$\mathscr{H}$为特征空间(希尔伯特空间),如果存在一个从$\chi$到$\mathscr{H}$的映射:
$\phi(x): \chi \rightarrow \mathscr{H}$
使得对所有$x,z\in \chi$, 函数$K(x,z)$满足条件:
$K(x,z) = \phi(x) \cdot \phi(z)$
则称$K(x,z)$为核函数,$\phi(x)$为映射函数。
核技巧的想法是,在学习和预测中只定义核函数$K(x,z)$,而不显式地定义映射函数$\phi$。通常,直接计算$K(x,z)$比较容易。
注意:$\phi$是输入空间到特征空间的映射,特征空间一般是高维的,甚至是无穷维的。对于给的的核$K(x,z)$,特征空间和映射函数的取法并不唯一,可以取不同特征空间,即便是同一特征空间,也可以取不同映射。
正定核
已知映射函数$\phi$,可以通过$\phi(x)$和$\phi(z)$的内积求得核函数$K(x,z)$。现在不用构造映射$\phi$能否直接判断一个给定的函数$K(x,z)$是不是核函数?或者说,函数$K(x,z)$满足什么条件才能成为核函数?
正定核的充要条件: 设 $K: \chi \times \chi \rightarrow R $是 对称函数,则$K(x,z)$为正定核函数的充要条件是对任意$x_i \in \chi, i=1,2,…, m$,$K(x,z)$对应的Gram矩阵:
$K = [K(x_i, x_j)]_{m \times m}$
是半正定矩阵。
注1:在李航老师的《统计学习方法》中,有详尽的解答。
该充要条件可以作为正定核,即核函数的另一定义:
正定核的等价定义: 设 $\chi \subset R^n$, $K(x,z)$是定义在$\chi \times \chi$上的对称函数,如果对任意$x_i \in \chi, i=1,2,…, m$,$K(x,z)$对应的Gram矩阵:
$K = [K(x_i, x_j)]_{m \times m}$
是半正定矩阵,则称$K(x,z)$是正定核。
注2:由Mercer定理($K$是核函数$\Leftrightarrow$核矩阵对称正定)可以得到Mercer核,正定核比Mercer核更具有一般性。
这一定义在构造核函数时很有用。但对于一个具体函数$K(x,z)$来说,检验它是否为正定核函数并不容易,因为要求对任意有限输入集${x_1, x_2, … , x_m}$验证$K$对应的Gram矩阵是否为半正定的。
在实际问题中往往应用已有的核函数。下面介绍常用的核函数。
常用核函数
- 多项式核函数(Polynomial kernel function)
$$ K(x, z) = (x \cdot z + 1)^p $$ - 高斯径向基函数(Radial basis function, RBF)
$$ K(x, z) = exp (- \frac{||x-z||^2}{2\sigma ^2})$$ 在此情形下,数据被提升到了无限维的空间。 - Sigmoid核
$$ K(x,z) = tanh(kx \cdot z + b) $$ $k,b$是超参,$k \gt 0, b \ge 0$。
核函数还具有以下性质:
假定:
- $K_1, K_2$都是定义在$\chi \times \chi, \chi \subseteq R^d$上的核
- $f$是定义在$\chi$上的实函数
- $\phi$是从$chi$到$R^m$上的一个特征映射
- $K_3$是定义在$R^m \times R^m$上的一个核
- $B$实一个对称正定的$d \times d$矩阵
则以下均为核函数:
- $K(a, b) = K_1(a, b) + K_2(a, b)$
- $K(a, b) = \alpha K_1(a, b)$
- $K(a, b) = K_1(a, b)K_2(a,b)$
- $K(a,b) = f(a)f(b)$
- $K(a,b) = K_3(\phi(a), \phi(b))$
- $K(a,b) = a^TBb$
一些与核相关的重要问题
- Q1: 怎么知道用哪一个核呢?
目前依然是一个开放问题,并没有确切答案。这也算是SVM的一个缺点。
- Q2: 如何确认用一个特定核之后,我们把数据映射到一个可以线性分隔开的高维空间了?
对于大多数的核函数,我们并不知道对应的映射函数$\phi(x)$,所以我们不知道数据被提升到多高的维度了。所以即使将数据提升到高维可以提高它们可被线性分隔开的概率,我们并不能保证完全分隔。
- Q3: 既然RBF将数据提升到了无限维,我们的数据在这样的空间总是线性可分的,为什么我们不都用RBF呢?
首先我们需要决定RBF里的$\sigma$的取值;其次,一个可以把数据提升到无限维空间的强核可能会导致严重的过拟合问题。
过拟合的一些特征:
- 小间隔(Margin),导致差的分类性能。
- 大量的支持向量(Support Vectors),降低计算速度。
- 如果我们再看一下核矩阵,那么它几乎是对角阵,意味着这些点是正交的,并且仅与自身相似。
软间隔与正则化
在前面的讨论中,我们一直假定训练样本在样本空间或者特征空间中是线性可分的,即存在一个超平面能将不同类的样本完全划分开。然而,在现实任务中,往往很难确定合适的核函数使得训练样本在特征空间中线性可分;退一步说,即便恰好找到了某个核函数使训练集在特征空间中线性可分,也很难断定这个貌似线性可分的结果不是由于过拟合所造成的。
缓解该问题的一个办法是允许支持向量机在一些样本上出错。为此,要引入“软间隔”(soft margin)的概念。
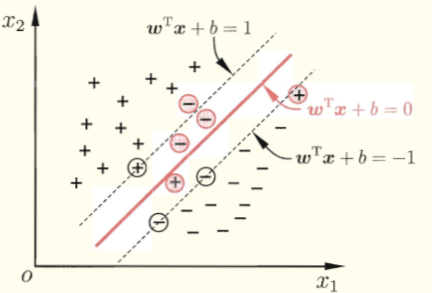
软间隔允许某些样本不满足约束:
我们引入松弛变量(slack variables)$\zeta_i$,对每一个样本都有对应的$\zeta_i$,表示样本$i$与理想位置的错误偏差。如果$0 \lt \zeta_i \lt 1$,那么样本分类正确,但处于margin区域;如果$\zeta_i \gt 1$,样本分类错误,处于超平面另一边。
现在,约束条件就变为:
最优化问题则是:
这就是常用的“软间隔支持向量机”。

于是,对任意训练样本$(x_i, y_i)$,总有$\alpha_i=0$或$y_if(x_i) = 1 - \zeta_i$.
- $\alpha_i = 0$,该样本不会对$f(x)$有任何影响
- $\alpha_i \gt 0$,则必有$y_if(x_i) = 1- \zeta_i$,即该样本是支持向量
- $\alpha_i \lt C$,则$\mu_i \gt 0$,进而有$\zeta_i = 0$,即该样本恰在最大间隔边界上;
- $\alpha_i = C$,则$\mu_i = 0$,此时若$\zeta_i \le 1$,则该样本落在最大间隔内部;若$\zeta_i \gt 1$,则该样本被错误分类
由此可以看出,软间隔支持向量机的最终模型仅与支持向量有关。
C问题:上面的分析中,C对于控制过拟合起了重要的作用,找到合适的C值也是SVM的主要问题之一。
- 较大的C:仅有较少的训练样本不在理想位置,这意味着较少的训练误差会对分类性能产生积极影响,但较小的间隔会对分类性能有负面影响。足够大的C会导致过拟合。
- 较小的C:更多的训练样本不在理想位置,意味着更多的训练误差会对分类性能产生负面影响,但较大的间隔对分类性能有正面作用。C足够小可能会导致欠拟合。
非线性可分SVM学习算法
输入:训练数据$T = {(x_1,y_1), (x_2,y_2),…, (x_N,y_N)}$,其中$x_i \in \chi = R^n, y_i \in {-1, +1}, i = 1, 2, …, N$
输出:分类决策函数
- 选择适当的核函数$K(x,z)$和适当的参数C,构造并求解最优化问题:
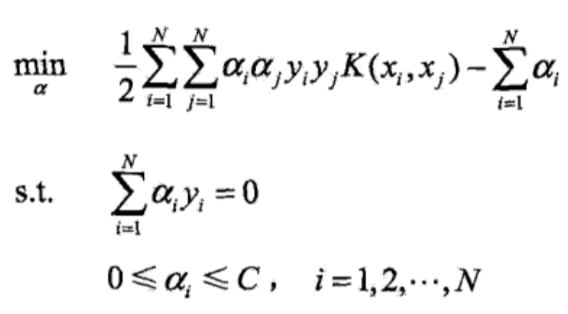 求得最优解$\alpha^{*} =(\alpha^{*}_1, \alpha^{*}_2,…,\alpha^{*}_N)^T$.
求得最优解$\alpha^{*} =(\alpha^{*}_1, \alpha^{*}_2,…,\alpha^{*}_N)^T$. - 选择$\alpha^{*}$的一个正分量$0 \lt \alpha^{*}_i \lt C$,计算
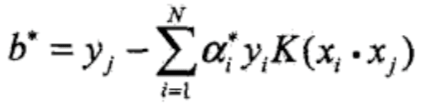
- 构造决策函数:
—–
以上就是SVM的主要内容了,文章写的仓促,有错误的话,还请各位指正!