
最近学习突然想到一些基本的问题,比如“为什么有那么多的激活函数?”,“这些激活函数背后的原理分别是什么?”,以及“什么时候用哪个激活函数效果更好?或者更能达到我们预期想要的结果。” “激活函数里面都是硬核的数学知识吗?”针对这些问题,重新把激活函数相关的内容学习了一下。
希望本文也可以帮助到对上面这些问题感到困惑、想不全、有些地方不太理解的小伙伴。
Activation Functions
神经网络的基本单元-神经元完成什么工作呢?简单地说,就是对输入求加权(w)和,再加上一个偏置(b)。
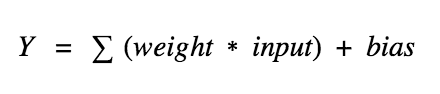
上式中,Y的取值范围可以是从负无穷到正无穷的整个实数域,神经元不知道这个值的边界,又怎么决定它是否被激活呢?
如何决定激活,是由激活函数来完成的。它检查神经元计算得到的Y**`的值,然后决定它是否被激活。激活函数充当了一个数学上“门”的作用,它沟通当前神经元的输入和它的输出(下一层的输入)。
3 Types of Activation Functions
Binary Step Function
决定激活还是不激活,最直观的,就是基于阈值的激活函数。如果Y高于阈值,就认为它被激活了;否则未被激活。功能上符合要求。
上面说的这种函数是“step function”,如下图:
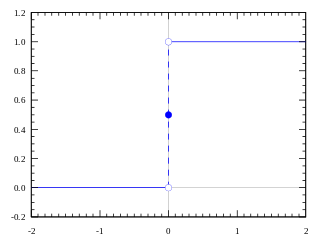
当value>0(threshold)的时候,输出是1(被激活),否则输出0(未被激活)。
尽管功能上符合要求,但是它有一定的缺点。对于二分类问题,step function能为我们提供的“1(yes)”或“0(no)”的选择。但是当面对多分类问题的时候,由于其只能输出0,1,当有多个1出现的时候,我们就不知道该激活哪一个了。
这个时候,我们需要类似中间激活值的东西,而不是直接告诉我们激活还是不激活(binary)。
我们从能想到的最简单的入手,线性函数。
Linear Function
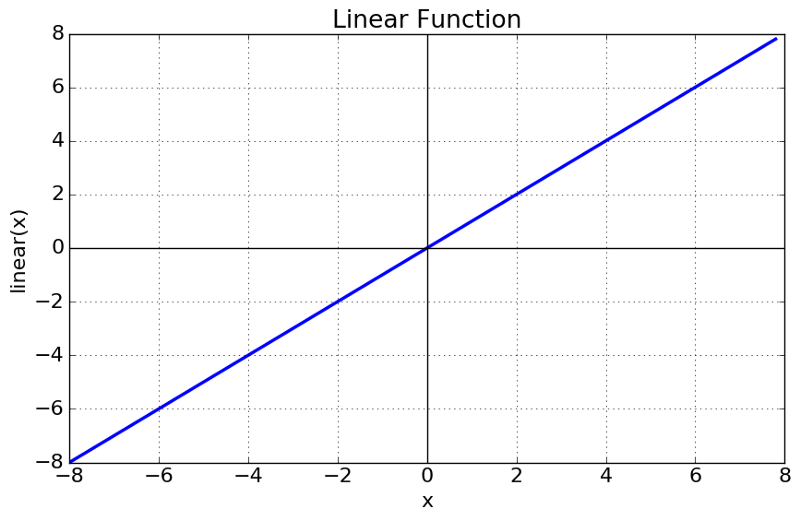
$$A = cx$$
一个简单的线性函数,激活和输入成比例,此时的激活值就不再是二元的,而是有一个范围。这样,我们可以把几个神经元连接在一起,如果超过1个激活,我们可以采用max(或softmax)来决定,所以这么做也符合功能需求。
它的问题是什么呢?
1. 无法利用Backpropagation(gradient descent)来训练模型:这个函数的导数是一个常量,和输入没有任何关系。这就意味着它反向传播的时候 ,输入对权重没有任何增益。
2. 整个网络的表达式坍塌成一个:线性函数的嵌套还是线性函数,所以不管网络有多少层,最后都变成一层。
一个使用线性激活函数的网络其实就是一个简单的线性回归模型。它限制了网络对于输入数据复杂多变参数的表达能力。
Non-linear Activation Functions
现在我们所使用的神经网络都使用非线性激活函数。它们允许模型在输入和输出之间创建更加复杂的映射,即有很强的表达能力,这对模型来说很重要,因为数据可能很复杂,比如图像、视频、音频以及哪些非线性或者高维的数据集。
当我们使用非线性激活函数的时候,在神经网络中几乎所有可能想象到的过程都可以一个函数计算来表达。
非线性函数解决了上述线性激活函数的问题:
1. 非线性允许反向传播,因为导数依赖于输入。
2. 允许堆叠层来构建一个深层神经网络。需要多个隐层神经元高准确率地学习复杂数据集。
下面介绍几种常见的非线性激活函数。
Several Common Nonlinear Activation Functions
Sigmoid/Logistic
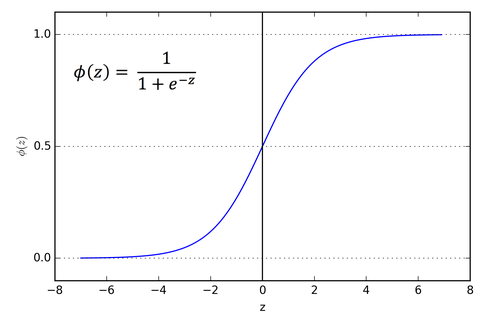
Advantages
- 它的梯度是平滑的,防止了输出值的“跳跃”。
- 输出值范围(0, 1),和线性函数的(-inf, inf)相比,避免了激活值爆炸。也规范化了每个神经元的输出。
- 预测清晰,当输入在[-2,2]之外时倾向于将Y值push到曲线的边缘,很接近1或0,使得预测变得更清晰。
Disadvantages
- 梯度消失:当输入X非常小或者非常大的时候,即梯度改变非常小,这将导致梯度消失问题,使得网络难以继续再学习下去。
- 输出不是以0为中心。
- 很消耗算力。
Tanh
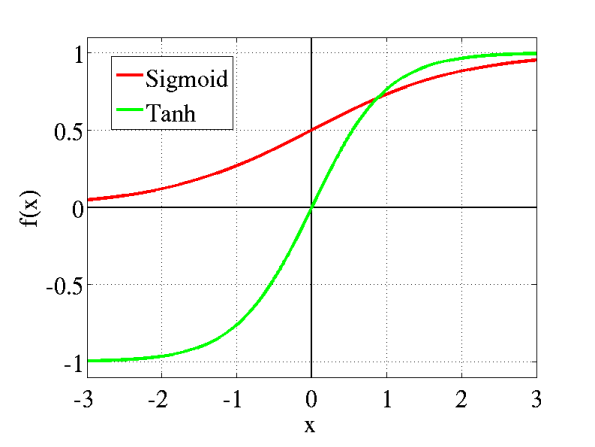
Tanh函数和Sigmoid相近,只多了一个优点——以0为中心:使得具有强烈的负、中性和强正值的输入更容易建模。
ReLU(Rectified Linear Unit)
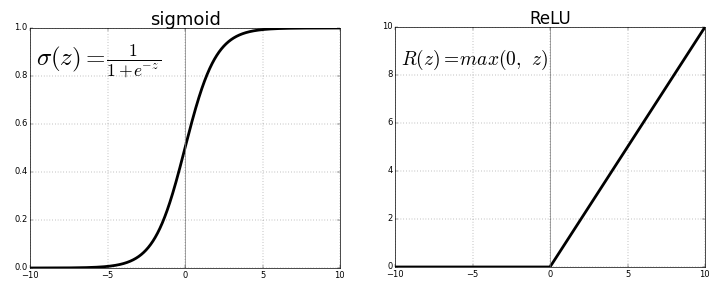
Advantages
- 计算高效:允许网络快速收敛
- 非线性:尽管这个函数看上去像是线性函数,但是ReLU的导数支持反向传播。
Disadvantages
- Dying ReLU问题——当输入接近0或负值时,梯度变为0,网络就不能进行反向传播与学习了。
Leaky ReLU
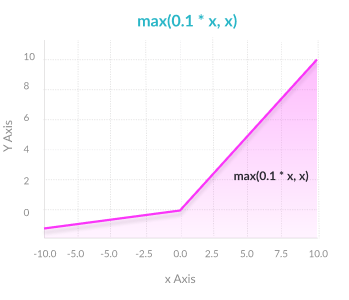
Advantages
- 阻止了Dying ReLU问题——作为ReLU的变种,它在输入为负值时,有一个小的正斜率,使得网络可以在输入负值的情况下反向传播。
- 其他类似ReLU
Disadvantages
- 结果不一致——Leaky ReLU对于负值不提供一致的预测。
Parametric ReLU
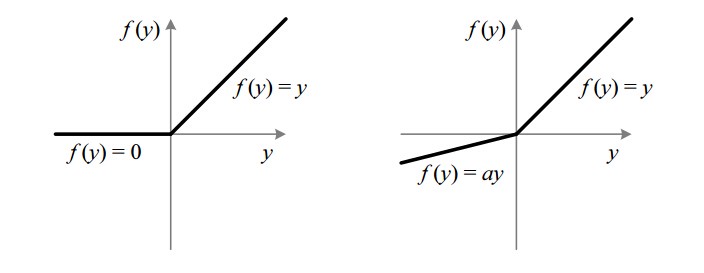
Advantages
- 输入是负值时,允许学习斜率。不同于Leaky ReLU,本方法将输入是负值时,函数的斜率作为参数,可进行学习。即有可能找到最适合的alpha。
- 其他类似ReLU
Disadvantages
- 对不同的问题可能有不同的表现。
Why derivative/differentiation is used?
反向传播时,我们需要知道更新方向以及步长,二者依赖于激活函数曲线的斜率,即导数。所以激活函数可微在机器学习中非常重要。
总结
在这篇博客里,简单回顾了一下神经网络中的激活函数。要点有二:一是为什么用非线性激活函数;二是各个非线性激活函数的优缺点。掌握了这两点,基本上对于什么时候用哪个激活函数都游刃有余了。
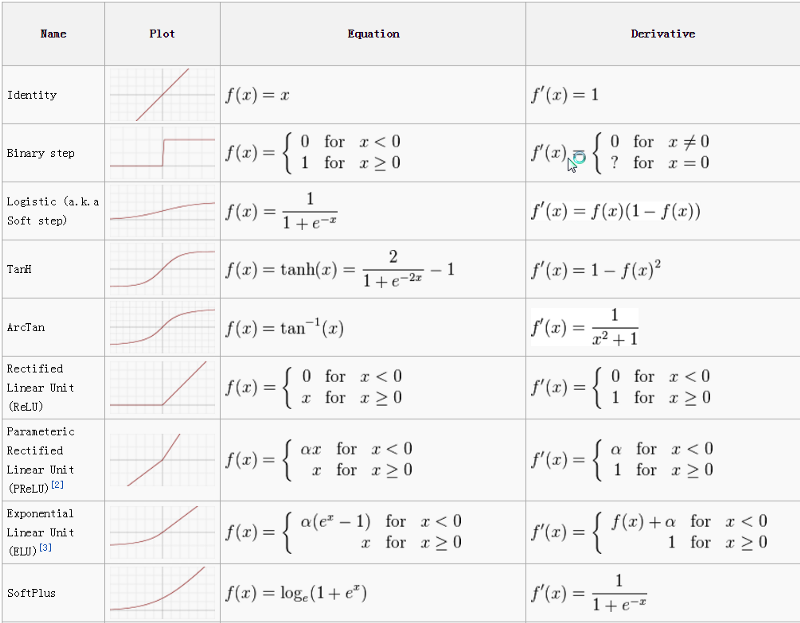
附录A-激活函数图表
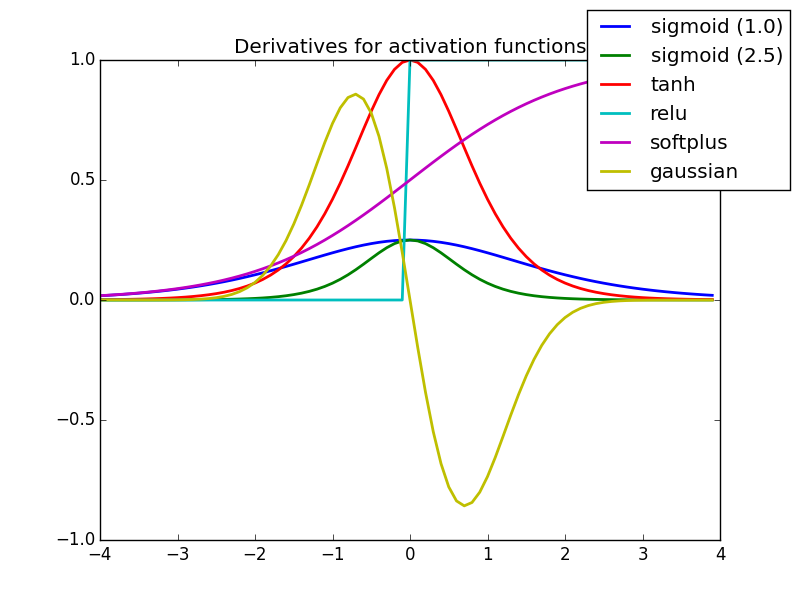
附录B-激活函数导数
References
Understanding Activation Functions in Neural Networks
Activation Functions in Neural Networks
7 Types of Neural Network Activation Functions